Fits generalized boosted regression models - new API. This
prepares the inputs, performing tasks such as creating cv folds,
before calling gbmt_fit to call the underlying C++ and fit
a generalized boosting model.
Usage
gbmt(
formula,
distribution = gbm_dist("Gaussian"),
data,
weights = rep(1, nrow(data)),
offset = rep(0, nrow(data)),
train_params = training_params(num_trees = 2000, interaction_depth = 3,
min_num_obs_in_node = 10, shrinkage = 0.001, bag_fraction = 0.5, id =
seq_len(nrow(data)), num_train = round(0.5 * nrow(data)), num_features = ncol(data) -
1),
var_monotone = NULL,
var_names = NULL,
cv_folds = 1,
cv_class_stratify = FALSE,
fold_id = NULL,
keep_gbm_data = FALSE,
par_details = getOption("gbm.parallel"),
is_verbose = FALSE
)Arguments
- formula
a symbolic description of the model to be fit. The formula may include an offset term (e.g. y~offset(n) + x).
- distribution
a
GBMDistobject specifying the distribution and any additional parameters needed. If not specified then the distribution will be guessed.- data
a data frame containing the variables in the model. By default, the variables are taken from the environment.
- weights
optional vector of weights used in the fitting process. These weights must be positive but need not be normalized. By default they are set to 1 for each data row.
- offset
optional vector specifying the model offset; must be positive. This defaults to a vector of 0's, the length of which is equal to the number rows of data.
- train_params
a GBMTrainParams object which specifies the parameters used in growing decision trees.
- var_monotone
optional vector, the same length as the number of predictors, indicating the relationship each variable has with the outcome. It have a monotone increasing (+1) or decreasing (-1) or an arbitrary relationship.
- var_names
a vector of strings of containing the names of the predictor variables.
- cv_folds
a positive integer specifying the number of folds to be used in cross-validation of the gbm fit. If cv_folds > 1 then cross-validation is performed; the default of cv_folds is 1.
- cv_class_stratify
a bool specifying whether or not to stratify via response outcome. Currently only applies to "Bernoulli" distribution and defaults to false.
- fold_id
An optional vector of values identifying what fold each observation is in. If supplied, cv_folds can be missing. Note: Multiple rows of the same observation must have the same fold_id.
- keep_gbm_data
a bool specifying whether or not the gbm_data object created in this method should be stored in the results.
- par_details
Details of the parallelization to use in the core algorithm (
gbmParallel).- is_verbose
if TRUE, gbmt will print out progress and performance of the fit.
Examples
## create some data
N <- 1000
X1 <- runif(N)
X2 <- runif(N)
X3 <- factor(sample(letters[1:4],N,replace=TRUE))
mu <- c(-1,0,1,2)[as.numeric(X3)]
p <- 1/(1+exp(-(sin(3*X1) - 4*X2 + mu)))
Y <- rbinom(N,1,p)
# random weights if you want to experiment with them
w <- rexp(N)
w <- N*w/sum(w)
data <- data.frame(Y=Y,X1=X1,X2=X2,X3=X3)
# \donttest{
# takes longer, but num_trees=3000 preferable
train_params <-
training_params(num_trees = 3000,
shrinkage = 0.001,
bag_fraction = 0.5,
num_train = N/2,
id=seq_len(nrow(data)),
min_num_obs_in_node = 10,
interaction_depth = 3,
num_features = 3)
# }
# for the example to run quickly, num_trees=100
train_params <-
training_params(num_trees = 100,
shrinkage = 0.001,
bag_fraction = 0.5,
num_train = N/2,
id=seq_len(nrow(data)),
min_num_obs_in_node = 10,
interaction_depth = 3,
num_features = 3)
# fit initial model
gbm1 <- gbmt(Y~X1+X2+X3, # formula
data=data, # dataset
weights=w,
var_monotone=c(0,0,0), # -1: monotone decrease,
# +1: monotone increase,
# 0: no monotone restrictions
distribution=gbm_dist("Bernoulli"),
train_params = train_params,
cv_folds=5, # do 5-fold cross-validation
is_verbose = FALSE) # don't print progress
# plot the performance
# returns out-of-bag estimated best number of trees
best.iter.oob <- gbmt_performance(gbm1,method="OOB")
#> Warning: OOB generally underestimates the optimal number of iterations although predictive performance is reasonably competitive. Using cv_folds>1 when calling gbm usually results in improved predictive performance.
plot(best.iter.oob)
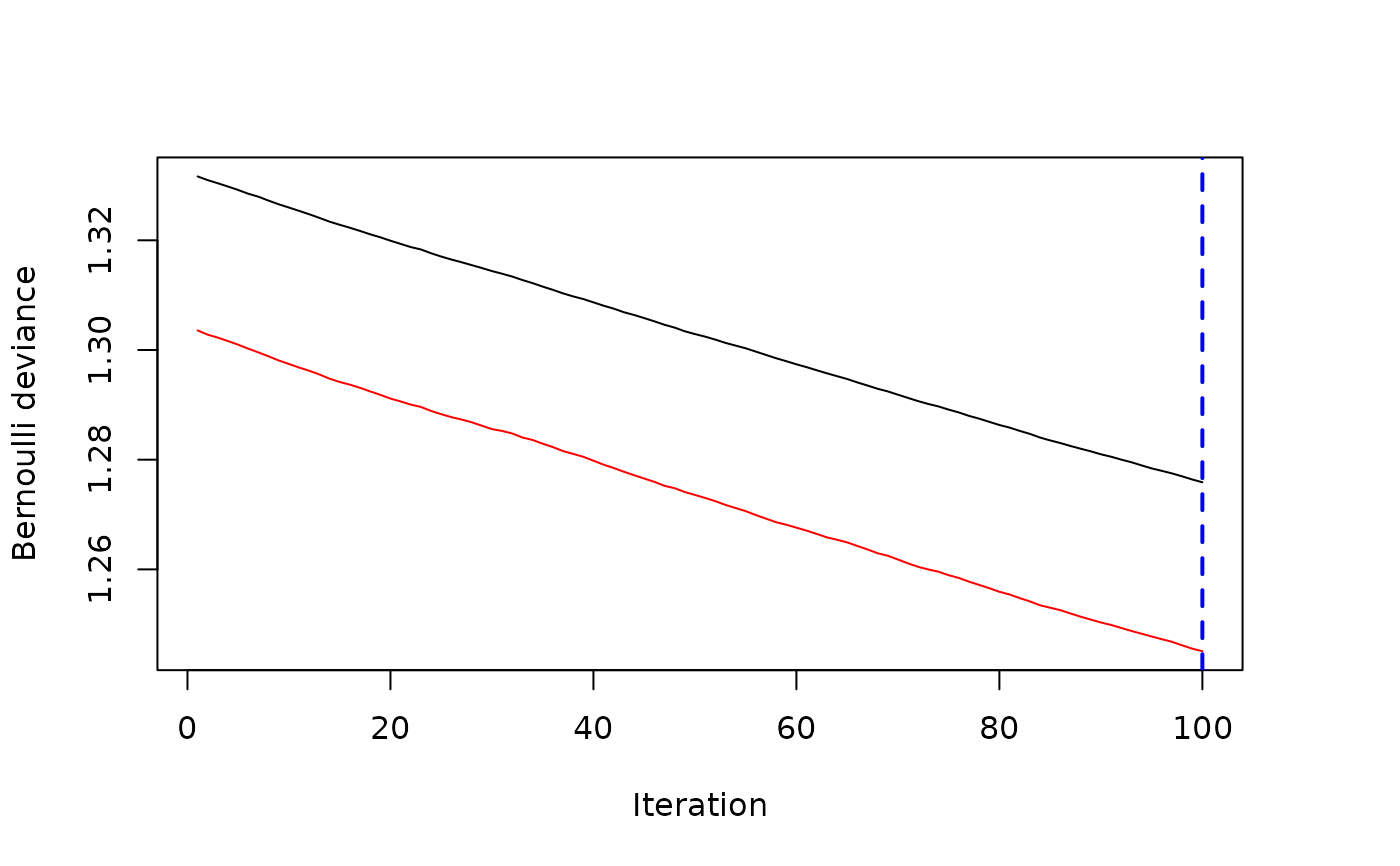 print(best.iter.oob)
#> The best out-of-bag iteration was 100.
# returns 5-fold cv estimate of best number of trees
best.iter.cv <- gbmt_performance(gbm1,method="cv")
plot(best.iter.cv)
print(best.iter.oob)
#> The best out-of-bag iteration was 100.
# returns 5-fold cv estimate of best number of trees
best.iter.cv <- gbmt_performance(gbm1,method="cv")
plot(best.iter.cv)
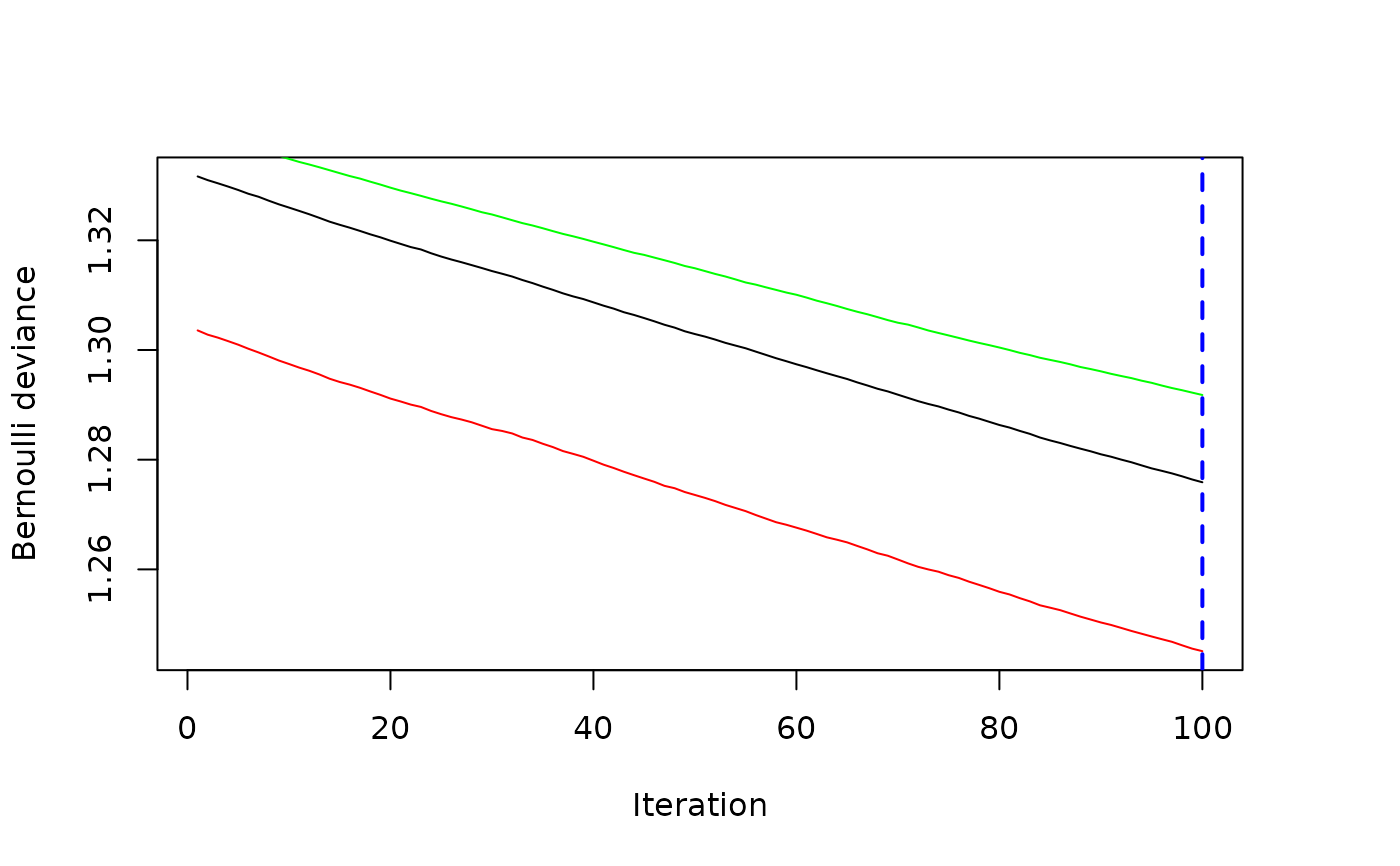 print(best.iter.cv)
#> The best cross-validation iteration was 100.
# returns test set estimate of best number of trees
best.iter.test <- gbmt_performance(gbm1,method="test")
plot(best.iter.cv)
print(best.iter.test)
#> The best test-set iteration was 100.
best.iter <- best.iter.test
# plot variable influence
summary(gbm1,num_trees=1) # based on first tree
print(best.iter.cv)
#> The best cross-validation iteration was 100.
# returns test set estimate of best number of trees
best.iter.test <- gbmt_performance(gbm1,method="test")
plot(best.iter.cv)
print(best.iter.test)
#> The best test-set iteration was 100.
best.iter <- best.iter.test
# plot variable influence
summary(gbm1,num_trees=1) # based on first tree
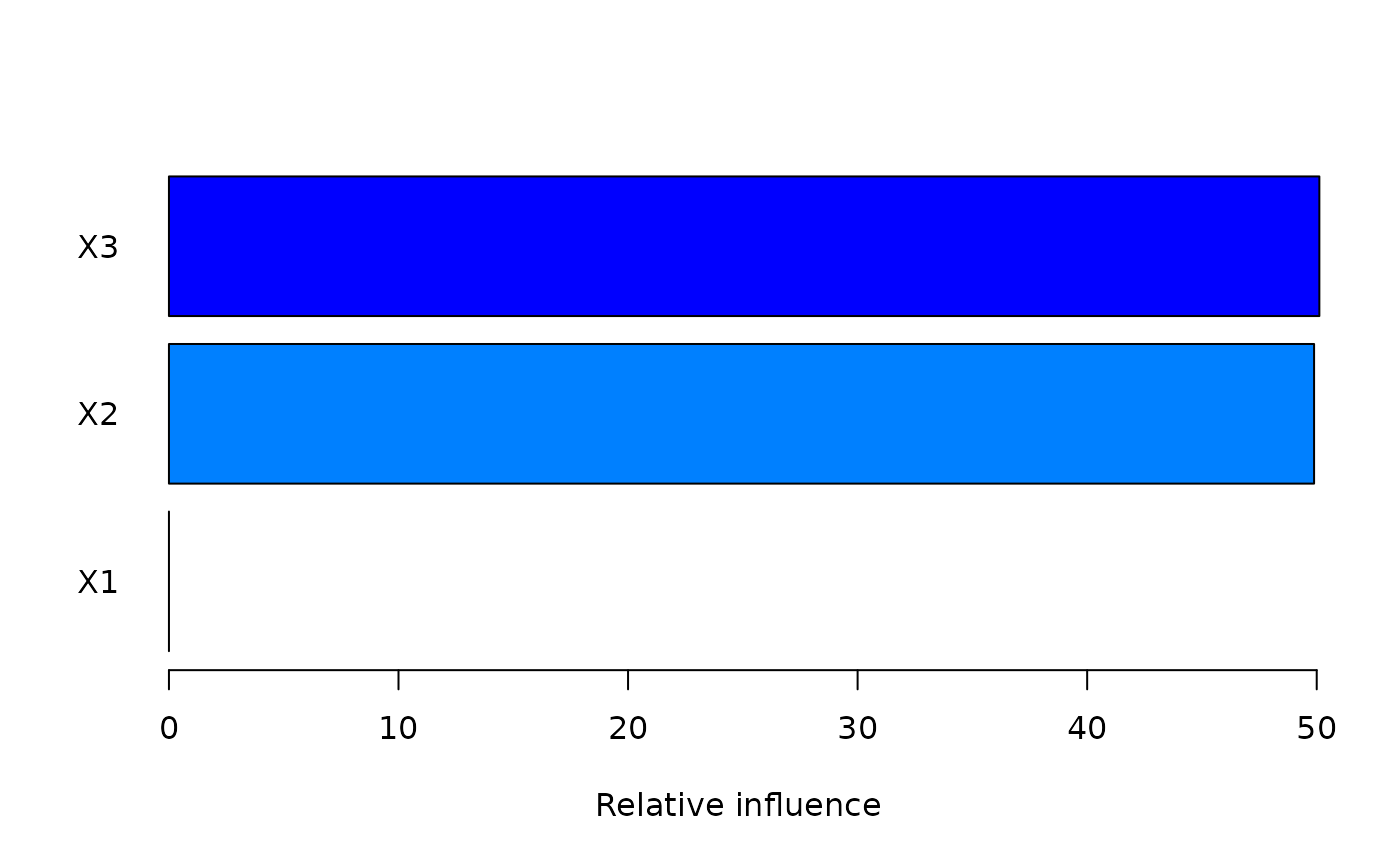 #> var rel_inf
#> X3 X3 50.11497
#> X2 X2 49.88503
#> X1 X1 0.00000
summary(gbm1,num_trees=best.iter) # based on estimated best number of trees
#> var rel_inf
#> X3 X3 50.11497
#> X2 X2 49.88503
#> X1 X1 0.00000
summary(gbm1,num_trees=best.iter) # based on estimated best number of trees
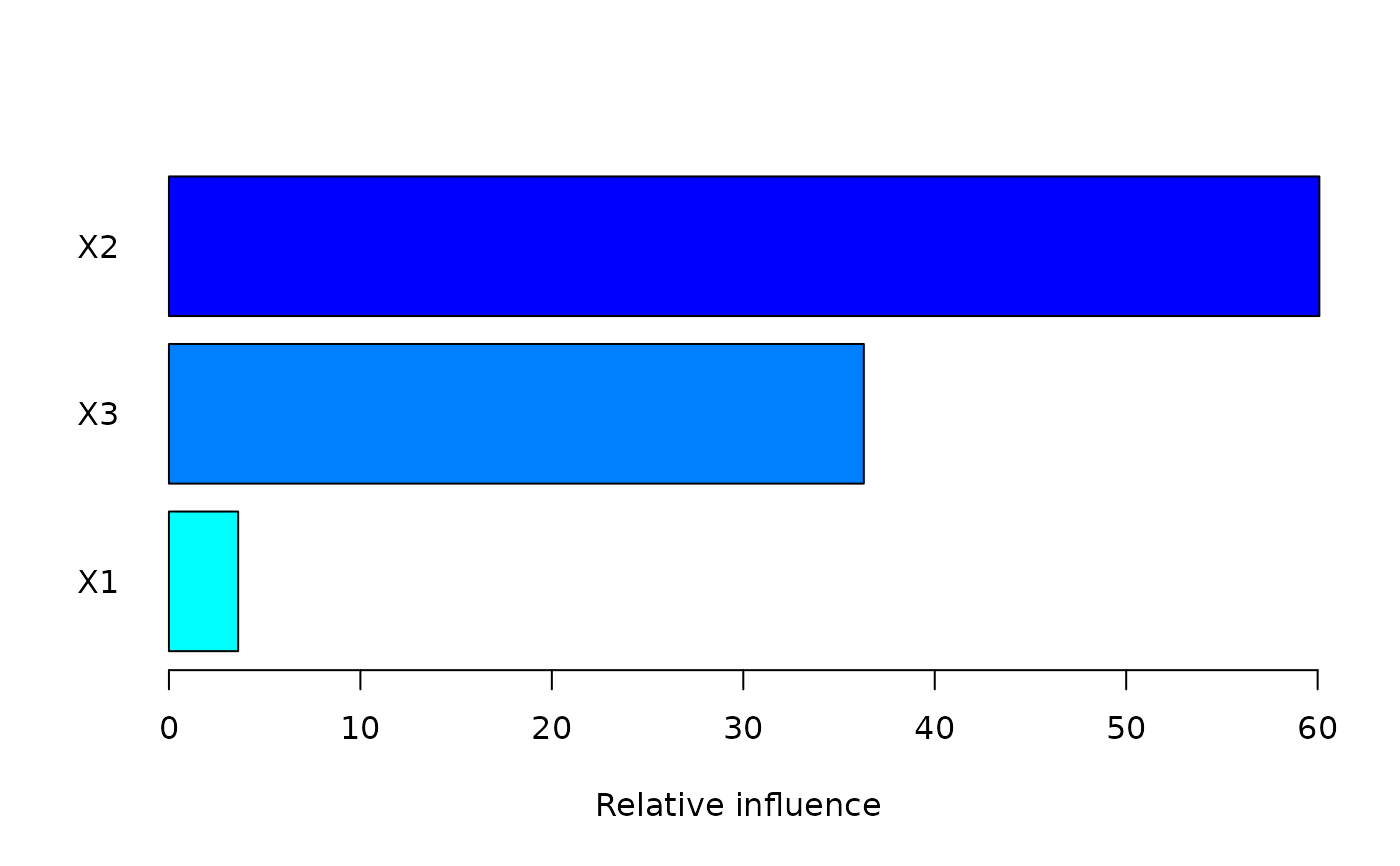 #> var rel_inf
#> X2 X2 60.089496
#> X3 X3 36.295607
#> X1 X1 3.614897
# create marginal plots
# plot variable X1,X2,X3 after "best" iterations
oldpar <- par(no.readonly = TRUE)
par(mfrow=c(1,3))
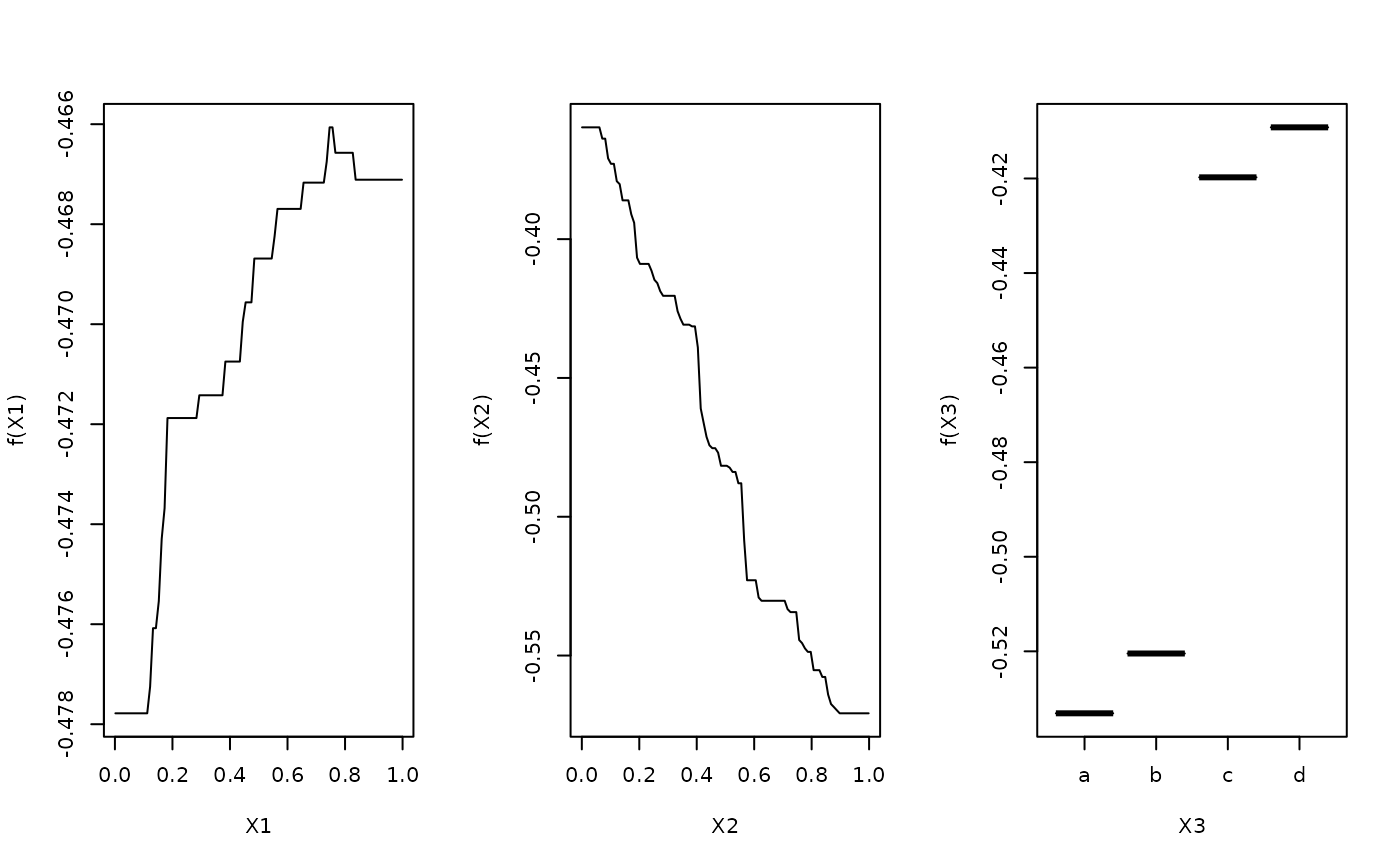
plot(gbm1,1,best.iter)
plot(gbm1,2,best.iter)
plot(gbm1,3,best.iter)
#> var rel_inf
#> X2 X2 60.089496
#> X3 X3 36.295607
#> X1 X1 3.614897
# create marginal plots
# plot variable X1,X2,X3 after "best" iterations
oldpar <- par(no.readonly = TRUE)
par(mfrow=c(1,3))
plot(gbm1,1,best.iter)
plot(gbm1,2,best.iter)
plot(gbm1,3,best.iter)
 par(mfrow=c(1,1))
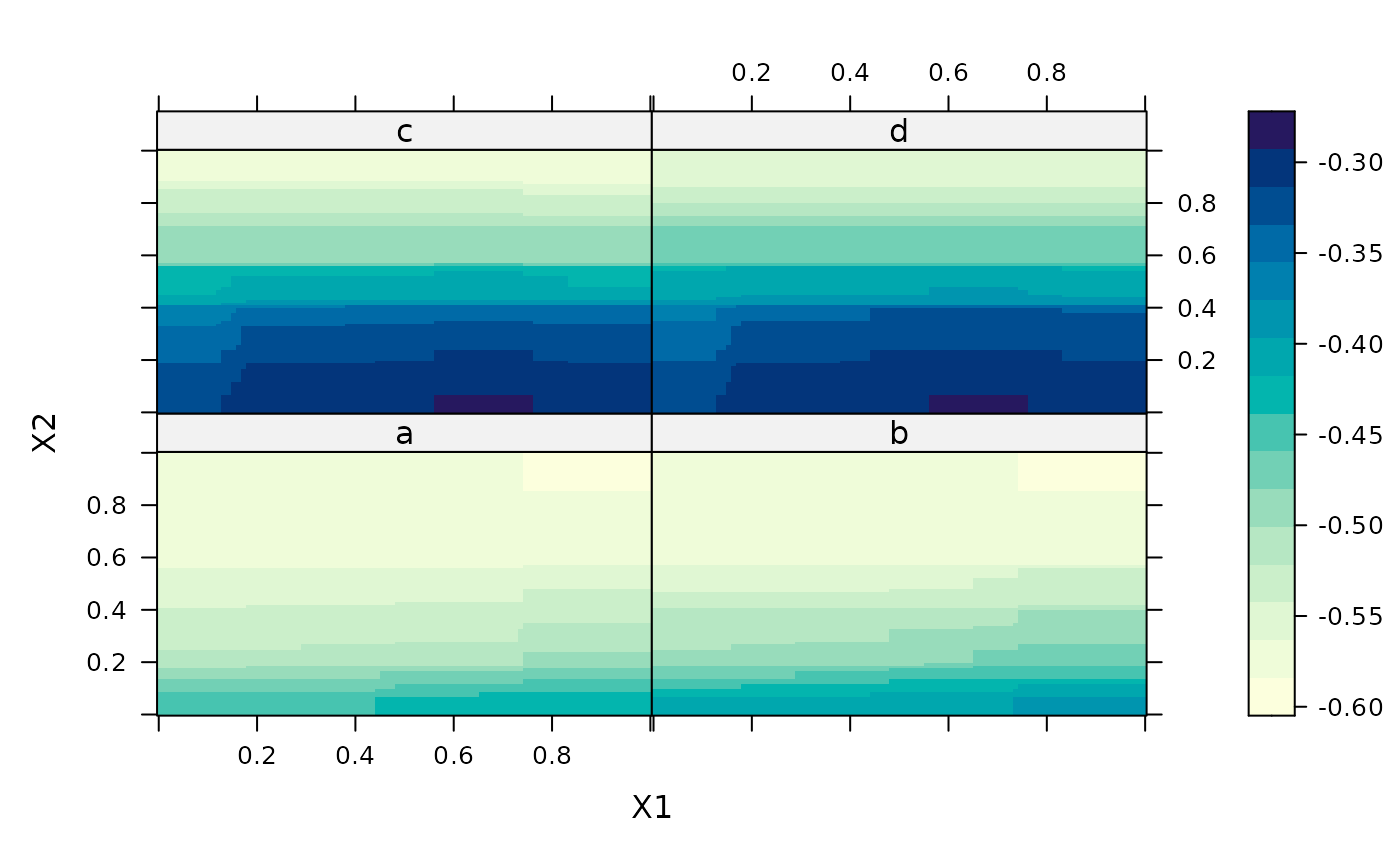
plot(gbm1,1:2,best.iter) # contour plot vars 1 & 2 after "best" num iterations
par(mfrow=c(1,1))
plot(gbm1,1:2,best.iter) # contour plot vars 1 & 2 after "best" num iterations
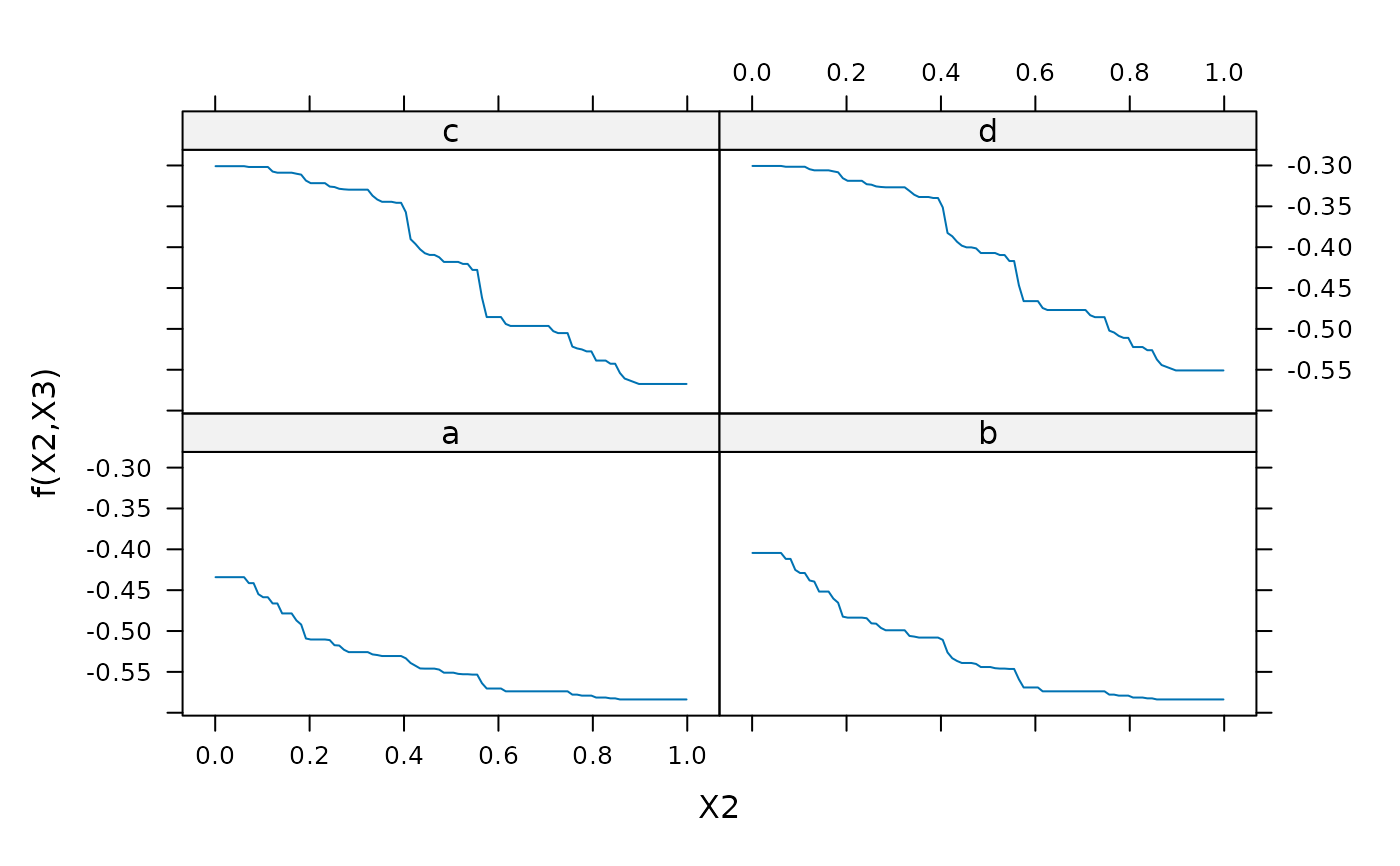
 plot(gbm1,2:3,best.iter) # lattice plot vars 2 & 3 after "best" num iterations
plot(gbm1,2:3,best.iter) # lattice plot vars 2 & 3 after "best" num iterations
 # 3-way plot
plot(gbm1,1:3,best.iter)
# 3-way plot
plot(gbm1,1:3,best.iter)
 # print the first and last trees
print(pretty_gbm_tree(gbm1,1))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction
#> 0 2 0.0000000000 1 5 9 13.002263
#> 1 1 0.1868964606 2 3 4 4.185183
#> 2 -1 0.0006839530 -1 -1 -1 0.000000
#> 3 -1 -0.0011356919 -1 -1 -1 0.000000
#> 4 -1 -0.0007574527 -1 -1 -1 0.000000
#> 5 1 0.6232625063 6 7 8 8.757422
#> 6 -1 0.0018095919 -1 -1 -1 0.000000
#> 7 -1 -0.0006186545 -1 -1 -1 0.000000
#> 8 -1 0.0011103692 -1 -1 -1 0.000000
#> 9 -1 0.0001493687 -1 -1 -1 0.000000
#> Weight Prediction
#> 0 266.46209 0.0001493687
#> 1 137.09561 -0.0007574527
#> 2 28.49728 0.0006839530
#> 3 108.59833 -0.0011356919
#> 4 137.09561 -0.0007574527
#> 5 129.36648 0.0011103692
#> 6 92.11491 0.0018095919
#> 7 37.25156 -0.0006186545
#> 8 129.36648 0.0011103692
#> 9 266.46209 0.0001493687
print(pretty_gbm_tree(gbm1, gbm1$params$num_trees))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction
#> 0 1 4.117486e-01 1 5 9 10.492596
#> 1 2 1.170000e+02 2 3 4 4.897472
#> 2 -1 -4.414465e-04 -1 -1 -1 0.000000
#> 3 -1 1.561599e-03 -1 -1 -1 0.000000
#> 4 -1 1.109272e-03 -1 -1 -1 0.000000
#> 5 2 1.180000e+02 6 7 8 2.670038
#> 6 -1 -1.232510e-03 -1 -1 -1 0.000000
#> 7 -1 5.034125e-05 -1 -1 -1 0.000000
#> 8 -1 -6.366327e-04 -1 -1 -1 0.000000
#> 9 -1 2.301956e-04 -1 -1 -1 0.000000
#> Weight Prediction
#> 0 242.47132 2.301956e-04
#> 1 120.38514 1.109272e-03
#> 2 27.18530 -4.414465e-04
#> 3 93.19984 1.561599e-03
#> 4 120.38514 1.109272e-03
#> 5 122.08618 -6.366327e-04
#> 6 65.37783 -1.232510e-03
#> 7 56.70835 5.034125e-05
#> 8 122.08618 -6.366327e-04
#> 9 242.47132 2.301956e-04
par(oldpar) # reset graphics options to previous settings
# print the first and last trees
print(pretty_gbm_tree(gbm1,1))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction
#> 0 2 0.0000000000 1 5 9 13.002263
#> 1 1 0.1868964606 2 3 4 4.185183
#> 2 -1 0.0006839530 -1 -1 -1 0.000000
#> 3 -1 -0.0011356919 -1 -1 -1 0.000000
#> 4 -1 -0.0007574527 -1 -1 -1 0.000000
#> 5 1 0.6232625063 6 7 8 8.757422
#> 6 -1 0.0018095919 -1 -1 -1 0.000000
#> 7 -1 -0.0006186545 -1 -1 -1 0.000000
#> 8 -1 0.0011103692 -1 -1 -1 0.000000
#> 9 -1 0.0001493687 -1 -1 -1 0.000000
#> Weight Prediction
#> 0 266.46209 0.0001493687
#> 1 137.09561 -0.0007574527
#> 2 28.49728 0.0006839530
#> 3 108.59833 -0.0011356919
#> 4 137.09561 -0.0007574527
#> 5 129.36648 0.0011103692
#> 6 92.11491 0.0018095919
#> 7 37.25156 -0.0006186545
#> 8 129.36648 0.0011103692
#> 9 266.46209 0.0001493687
print(pretty_gbm_tree(gbm1, gbm1$params$num_trees))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction
#> 0 1 4.117486e-01 1 5 9 10.492596
#> 1 2 1.170000e+02 2 3 4 4.897472
#> 2 -1 -4.414465e-04 -1 -1 -1 0.000000
#> 3 -1 1.561599e-03 -1 -1 -1 0.000000
#> 4 -1 1.109272e-03 -1 -1 -1 0.000000
#> 5 2 1.180000e+02 6 7 8 2.670038
#> 6 -1 -1.232510e-03 -1 -1 -1 0.000000
#> 7 -1 5.034125e-05 -1 -1 -1 0.000000
#> 8 -1 -6.366327e-04 -1 -1 -1 0.000000
#> 9 -1 2.301956e-04 -1 -1 -1 0.000000
#> Weight Prediction
#> 0 242.47132 2.301956e-04
#> 1 120.38514 1.109272e-03
#> 2 27.18530 -4.414465e-04
#> 3 93.19984 1.561599e-03
#> 4 120.38514 1.109272e-03
#> 5 122.08618 -6.366327e-04
#> 6 65.37783 -1.232510e-03
#> 7 56.70835 5.034125e-05
#> 8 122.08618 -6.366327e-04
#> 9 242.47132 2.301956e-04
par(oldpar) # reset graphics options to previous settings