Fits generalized boosted regression models.
Usage
gbm.fit(
x,
y,
offset = NULL,
distribution = "bernoulli",
w = NULL,
var.monotone = NULL,
n.trees = 100,
interaction.depth = 1,
n.minobsinnode = 10,
shrinkage = 0.001,
bag.fraction = 0.5,
nTrain = NULL,
train.fraction = NULL,
mFeatures = NULL,
keep.data = TRUE,
verbose = TRUE,
var.names = NULL,
response.name = "y",
group = NULL,
tied.times.method = "efron",
prior.node.coeff.var = 1000,
strata = NA,
obs.id = 1:nrow(x)
)
gbm(
formula = formula(data),
distribution = "bernoulli",
data = list(),
weights,
subset = NULL,
offset = NULL,
var.monotone = NULL,
n.trees = 100,
interaction.depth = 1,
n.minobsinnode = 10,
shrinkage = 0.001,
bag.fraction = 0.5,
train.fraction = 1,
mFeatures = NULL,
cv.folds = 0,
keep.data = TRUE,
verbose = FALSE,
class.stratify.cv = NULL,
n.cores = NULL,
par.details = getOption("gbm.parallel"),
fold.id = NULL,
tied.times.method = "efron",
prior.node.coeff.var = 1000,
strata = NA,
obs.id = 1:nrow(data)
)Arguments
- x, y
For
gbm.fit:xis a data frame or data matrix containing the predictor variables andyis a matrix of outcomes. Excludingcoxphthis matrix of outcomes collapses to a vector, in the case ofcoxphit is a survival object where the event times fill the first one (or two columns) and the status fills the final column. The number of rows inxmust be the same as the length of the 1st dimension ofy.- offset
an optional model offset
- distribution
either a character string specifying the name of the distribution to use or a list with a component
namespecifying the distribution and any additional parameters needed. If not specified,gbmwill try to guess: if the response has only two unique values, bernoulli is assumed (two-factor responses are converted to 0,1); otherwise, if the response has class "Surv", coxph is assumed; otherwise, gaussian is assumed.Available distributions are "gaussian" (squared error), "laplace" (absolute loss), "tdist" (t-distribution loss), "bernoulli" (logistic regression for 0-1 outcomes), "huberized" (Huberized hinge loss for 0-1 outcomes), "adaboost" (the AdaBoost exponential loss for 0-1 outcomes), "poisson" (count outcomes), "coxph" (right censored observations), "quantile", or "pairwise" (ranking measure using the LambdaMART algorithm).
If quantile regression is specified,
distributionmust be a list of the formlist(name="quantile",alpha=0.25)wherealphais the quantile to estimate. Non-constant weights are unsupported.If "tdist" is specified, the default degrees of freedom is four and this can be controlled by specifying
distribution=list(name="tdist", df=DF)whereDFis your chosen degrees of freedom.If "pairwise" regression is specified,
distributionmust be a list of the formlist(name="pairwise",group=...,metric=...,max.rank=...)(metricandmax.rankare optional, see below).groupis a character vector with the column names ofdatathat jointly indicate the group an instance belongs to (typically a query in Information Retrieval applications). For training, only pairs of instances from the same group and with different target labels can be considered.metricis the IR measure to use, one of- list("conc")
Fraction of concordant pairs; for binary labels, this is equivalent to the Area under the ROC Curve
- :
Fraction of concordant pairs; for binary labels, this is equivalent to the Area under the ROC Curve
- list("mrr")
Mean reciprocal rank of the highest-ranked positive instance
- :
Mean reciprocal rank of the highest-ranked positive instance
- list("map")
Mean average precision, a generalization of
mrrto multiple positive instances- :
Mean average precision, a generalization of
mrrto multiple positive instances- list("ndcg:")
Normalized discounted cumulative gain. The score is the weighted sum (DCG) of the user-supplied target values, weighted by log(rank+1), and normalized to the maximum achievable value. This is the default if the user did not specify a metric.
ndcgandconcallow arbitrary target values, while binary targets {0,1} are expected formapandmrr. Forndcgandmrr, a cut-off can be chosen using a positive integer parametermax.rank. If left unspecified, all ranks are taken into account.Note that splitting of instances into training and validation sets follows group boundaries and therefore only approximates the specified
train.fractionratio (the same applies to cross-validation folds). Internally queries are randomly shuffled before training to avoid bias.Weights can be used in conjunction with pairwise metrics, however it is assumed that they are constant for instances from the same group.
For details and background on the algorithm, see e.g. Burges (2010).
- w
For
gbm.fit:wis a vector of weights of the same length as the 1st dimension ofy.- var.monotone
an optional vector, the same length as the number of predictors, indicating which variables have a monotone increasing (+1), decreasing (-1), or arbitrary (0) relationship with the outcome.
- n.trees
the total number of trees to fit. This is equivalent to the number of iterations and the number of basis functions in the additive expansion.
- interaction.depth
The maximum depth of variable interactions: 1 builds an additive model, 2 builds a model with up to two-way interactions, etc.
- n.minobsinnode
minimum number of observations (not total weights) in the terminal nodes of the trees.
- shrinkage
a shrinkage parameter applied to each tree in the expansion. Also known as the learning rate or step-size reduction.
- bag.fraction
the fraction of independent training observations (or patients) randomly selected to propose the next tree in the expansion, depending on the obs.id vector multiple training data rows may belong to a single 'patient'. This introduces randomness into the model fit. If
bag.fraction<1 then running the same model twice will result in similar but different fits.gbmuses the R random number generator, soset.seedensures the same model can be reconstructed. Preferably, the user can save the returnedGBMFitobject usingsave.- nTrain
An integer representing the number of unique patients, each patient could have multiple rows associated with them, on which to train. This is the preferred way of specification for
gbm.fit; The optiontrain.fractioningbm.fitis deprecated and only maintained for backward compatibility. These two parameters are mutually exclusive. If both are unspecified, all data is used for training.- train.fraction
The first
train.fraction * nrows(data)observations are used to fit thegbmand the remainder are used for computing out-of-sample estimates of the loss function.- mFeatures
Each node will be trained on a random subset of
mFeaturesnumber of features. Each node will consider a new random subset of features, adding variability to tree growth and reducing computation time.mFeatureswill be bounded between 1 andnCols. Values outside of this bound will be set to the lower or upper limits.- keep.data
a logical variable indicating whether to keep the data and an index of the data stored with the object. Keeping the data and index makes subsequent calls to
gbm_morefaster at the cost of storing an extra copy of the dataset.- verbose
If TRUE, gbm will print out progress and performance indicators. If this option is left unspecified for gbm_more then it uses
verbosefromobject.- var.names
For
gbm.fit: A vector of strings of length equal to the number of columns ofxcontaining the names of the predictor variables.- response.name
For
gbm.fit: A character string label for the response variable.- group
groupused whendistribution = 'pairwise'.- tied.times.method
For
gbmandgbm.fit: This is an optional string used withCoxPHdistribution specifying what method to employ when dealing with tied times. Currently only "efron" and "breslow" are available; the default value is "efron". Setting the string to any other value reverts the method to the original CoxPH model implementation where ties are not explicitly dealt with.- prior.node.coeff.var
Optional double only used with the
coxphdistribution. It is a prior on the coefficient of variation associated with the hazard rate assigned to each terminal node when fitting a tree.Increasing its value emphasises the importance of the training data in the node when assigning a prediction to said node.- strata
Optional vector of integers (or factors) only used with the
coxphdistributions. Each integer in this vector represents the stratum the corresponding row in the data belongs to, e. g. if the 10th element is 3 then the 10th data row belongs to the 3rd strata.- obs.id
Optional vector of integers used to specify which rows of data belong to individual patients. Data is then bagged by patient id; the default sets each row of the data to belong to an individual patient.
- formula
a symbolic description of the model to be fit. The formula may include an offset term (e.g. y~offset(n)+x). If
keep.data=FALSEin the initial call togbmthen it is the user's responsibility to resupply the offset togbm_more.- data
an optional data frame containing the variables in the model. By default the variables are taken from
environment(formula), typically the environment from whichgbmis called. Ifkeep.data=TRUEin the initial call togbmthengbmstores a copy with the object. Ifkeep.data=FALSEthen subsequent calls togbm_moremust resupply the same dataset. It becomes the user's responsibility to resupply the same data at this point.- weights
an optional vector of weights to be used in the fitting process. The weights must be positive but do not need to be normalized. If
keep.data=FALSEin the initial call togbm, then it is the user's responsibility to resupply the weights togbm_more.- subset
an optional vector defining a subset of the data to be used
- cv.folds
Number of cross-validation folds to perform. If
cv.folds>1 thengbm, in addition to the usual fit, will perform a cross-validation and calculate an estimate of generalization error returned incv_error.- class.stratify.cv
whether the cross-validation should be stratified by class. Is only implemented for
bernoulli. The purpose of stratifying the cross-validation is to help avoiding situations in which training sets do not contain all classes.- n.cores
number of cores to use for parallelization. Please use
par.detailsinstead; this argument is only provided for convenience.- par.details
Details of the parallelization to use in the core algorithm.
- fold.id
An optional vector of values identifying what fold each observation is in. If supplied, cv.folds can be missing. Note: Multiple observations to the same patient must have the same fold id.
Details
See the gbm vignette for technical details.
This package implements the generalized boosted modeling framework. Boosting is the process of iteratively adding basis functions in a greedy fashion so that each additional basis function further reduces the selected loss function. This implementation closely follows Friedman's Gradient Boosting Machine (Friedman, 2001).
In addition to many of the features documented in the Gradient
Boosting Machine, gbm offers additional features including
the out-of-bag estimator for the optimal number of iterations, the
ability to store and manipulate the resulting GBMFit object,
and a variety of other loss functions that had not previously had
associated boosting algorithms, including the Cox partial
likelihood for censored data, the poisson likelihood for count
outcomes, and a gradient boosting implementation to minimize the
AdaBoost exponential loss function.
gbm is a deprecated function that now acts as a front-end to
gbmt_fit that uses the familiar R modeling
formulas. However, model.frame is very slow if
there are many predictor variables. For power users with many
variables use gbm.fit over gbm; however gbmt
and gbmt_fit are now the current APIs.
References
Y. Freund and R.E. Schapire (1997) “A decision-theoretic generalization of on-line learning and an application to boosting,” Journal of Computer and System Sciences, 55(1):119-139.
G. Ridgeway (1999). “The state of boosting,” Computing Science and Statistics 31:172-181.
J.H. Friedman, T. Hastie, R. Tibshirani (2000). “Additive Logistic Regression: a Statistical View of Boosting,” Annals of Statistics 28(2):337-374.
J.H. Friedman (2001). “Greedy Function Approximation: A Gradient Boosting Machine,” Annals of Statistics 29(5):1189-1232.
J.H. Friedman (2002). “Stochastic Gradient Boosting,” Computational Statistics and Data Analysis 38(4):367-378.
B. Kriegler (2007). Cost-Sensitive Stochastic Gradient Boosting Within a Quantitative Regression Framework. PhD dissertation, UCLA Statistics.
C. Burges (2010). “From RankNet to LambdaRank to LambdaMART: An Overview,” Microsoft Research Technical Report MSR-TR-2010-82.
Author
James Hickey, Greg Ridgeway gregridgeway@gmail.com
Quantile regression code developed by Brian Kriegler bk@stat.ucla.edu
t-distribution code developed by Harry Southworth and Daniel Edwards
Pairwise code developed by Stefan Schroedl schroedl@a9.com
Examples
# A least squares regression example # create some data
N <- 1000
X1 <- runif(N)
X2 <- 2*runif(N)
X3 <- ordered(sample(letters[1:4],N,replace=TRUE),levels=letters[4:1])
X4 <- factor(sample(letters[1:6],N,replace=TRUE))
X5 <- factor(sample(letters[1:3],N,replace=TRUE))
X6 <- 3*runif(N)
mu <- c(-1,0,1,2)[as.numeric(X3)]
SNR <- 10 # signal-to-noise ratio
Y <- X1**1.5 + 2 * (X2**.5) + mu
sigma <- sqrt(var(Y)/SNR)
Y <- Y + rnorm(N,0,sigma)
# introduce some missing values
X1[sample(1:N,size=500)] <- NA
X4[sample(1:N,size=300)] <- NA
data <- data.frame(Y=Y,X1=X1,X2=X2,X3=X3,X4=X4,X5=X5,X6=X6)
# fit initial model
gbm1 <-
gbm(Y~X1+X2+X3+X4+X5+X6, # formula
data=data, # dataset
var.monotone=c(0,0,0,0,0,0), # -1: monotone decrease,
# +1: monotone increase,
# 0: no monotone restrictions
distribution="gaussian", # see the help for other choices
n.trees=1000, # number of trees
shrinkage=0.05, # shrinkage or learning rate,
# 0.001 to 0.1 usually work
interaction.depth=3, # 1: additive model, 2: two-way interactions, etc.
bag.fraction = 0.5, # subsampling fraction, 0.5 is probably best
train.fraction = 0.5, # fraction of data for training,
# first train.fraction*N used for training
mFeatures = 3, # half of the features are considered at each node
n.minobsinnode = 10, # minimum total weight needed in each node
cv.folds = 3, # do 3-fold cross-validation
keep.data=TRUE, # keep a copy of the dataset with the object
verbose=FALSE # don't print out progress
# , par.details=gbmParallel(num_threads=15) # option for gbm3 to parallelize
)
# check performance using an out-of-bag estimator
# OOB underestimates the optimal number of iterations
best_iter <- gbmt_performance(gbm1,method="OOB")
#> Warning: OOB generally underestimates the optimal number of iterations although predictive performance is reasonably competitive. Using cv_folds>1 when calling gbm usually results in improved predictive performance.
print(best_iter)
#> The best out-of-bag iteration was 99.
# check performance using a 50% heldout test set
best_iter <- gbmt_performance(gbm1,method="test")
print(best_iter)
#> The best test-set iteration was 160.
# check performance using 3-fold cross-validation
best_iter <- gbmt_performance(gbm1,method="cv")
print(best_iter)
#> The best cross-validation iteration was 146.
# plot the performance # plot variable influence
summary(gbm1, num_trees=1) # based on the first tree
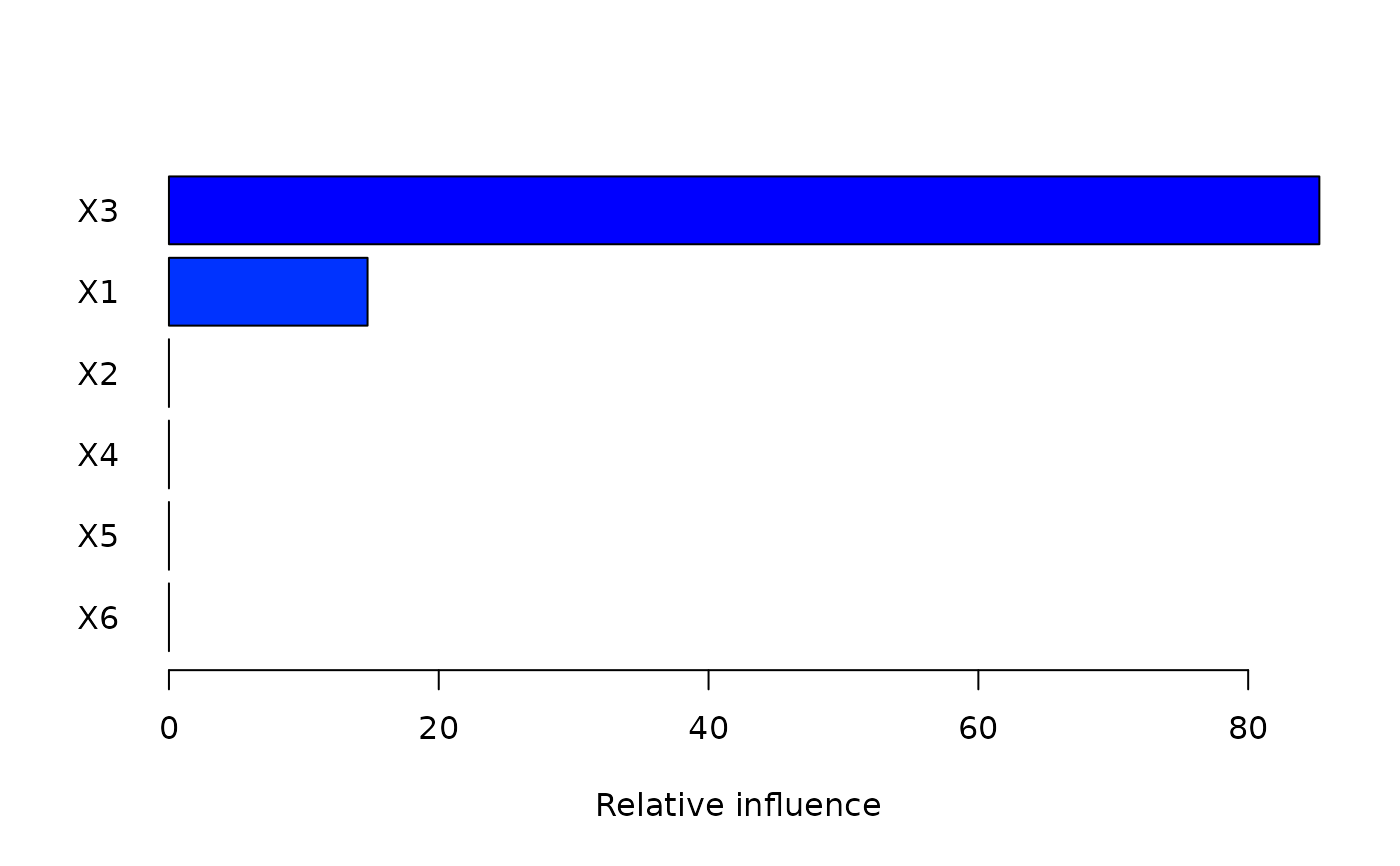 #> var rel_inf
#> X3 X3 85.27699
#> X1 X1 14.72301
#> X2 X2 0.00000
#> X4 X4 0.00000
#> X5 X5 0.00000
#> X6 X6 0.00000
summary(gbm1, num_trees=best_iter) # based on the estimated best number of trees
#> var rel_inf
#> X3 X3 85.27699
#> X1 X1 14.72301
#> X2 X2 0.00000
#> X4 X4 0.00000
#> X5 X5 0.00000
#> X6 X6 0.00000
summary(gbm1, num_trees=best_iter) # based on the estimated best number of trees
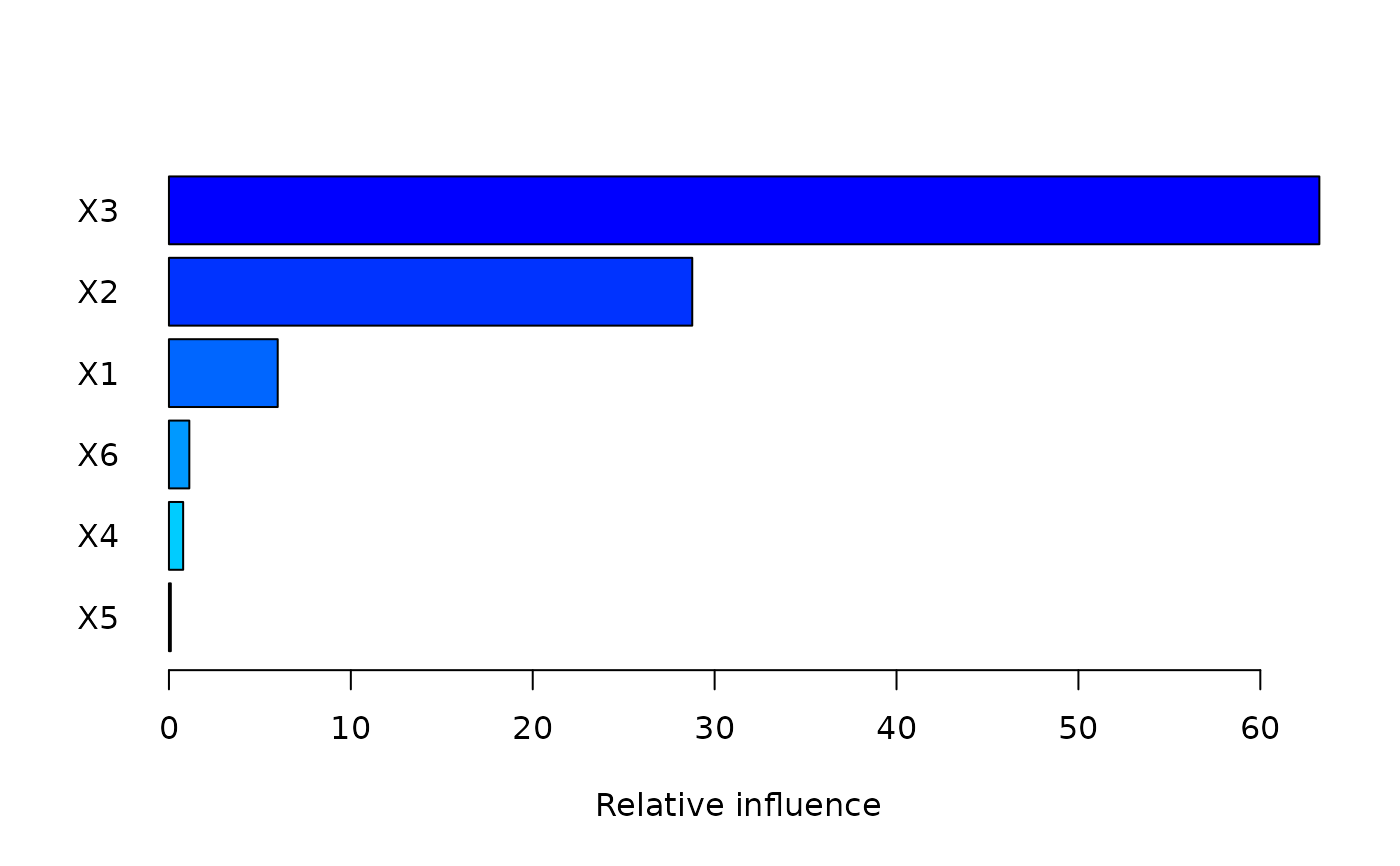 #> var rel_inf
#> X3 X3 63.2461194
#> X2 X2 28.7697296
#> X1 X1 5.9798260
#> X6 X6 1.1201571
#> X4 X4 0.7813982
#> X5 X5 0.1027697
# compactly print the first and last trees for curiosity
print(pretty_gbm_tree(gbm1,1))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction Weight
#> 0 0 0.5169642128 1 5 6 30.69864 250
#> 1 2 0.5000000000 2 3 4 70.28915 67
#> 2 -1 -0.0974371920 -1 -1 -1 0.00000 23
#> 3 -1 0.0104230254 -1 -1 -1 0.00000 44
#> 4 -1 -0.0266036164 -1 -1 -1 0.00000 67
#> 5 -1 0.0208285473 -1 -1 -1 0.00000 68
#> 6 2 2.5000000000 7 8 9 107.52019 115
#> 7 -1 -0.0290981596 -1 -1 -1 0.00000 83
#> 8 -1 0.0787840681 -1 -1 -1 0.00000 32
#> 9 -1 0.0009212429 -1 -1 -1 0.00000 115
#> Prediction
#> 0 -0.0010406326
#> 1 -0.0266036164
#> 2 -0.0974371920
#> 3 0.0104230254
#> 4 -0.0266036164
#> 5 0.0208285473
#> 6 0.0009212429
#> 7 -0.0290981596
#> 8 0.0787840681
#> 9 0.0009212429
print(pretty_gbm_tree(gbm1,gbm1$params$num_trees))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction Weight
#> 0 1 1.2225338528 1 5 9 0.3614331 250
#> 1 5 0.2508527830 2 3 4 0.2505685 145
#> 2 -1 0.0041388708 -1 -1 -1 0.0000000 15
#> 3 -1 -0.0026860866 -1 -1 -1 0.0000000 130
#> 4 -1 -0.0019800565 -1 -1 -1 0.0000000 145
#> 5 5 2.2890534288 6 7 8 0.4646160 105
#> 6 -1 0.0035842050 -1 -1 -1 0.0000000 83
#> 7 -1 -0.0045884162 -1 -1 -1 0.0000000 22
#> 8 -1 0.0018718463 -1 -1 -1 0.0000000 105
#> 9 -1 -0.0003622573 -1 -1 -1 0.0000000 250
#> Prediction
#> 0 -0.0003622573
#> 1 -0.0019800565
#> 2 0.0041388708
#> 3 -0.0026860866
#> 4 -0.0019800565
#> 5 0.0018718463
#> 6 0.0035842050
#> 7 -0.0045884162
#> 8 0.0018718463
#> 9 -0.0003622573
# make some new data
N <- 1000
X1 <- runif(N)
X2 <- 2*runif(N)
X3 <- ordered(sample(letters[1:4],N,replace=TRUE))
X4 <- factor(sample(letters[1:6],N,replace=TRUE))
X5 <- factor(sample(letters[1:3],N,replace=TRUE))
X6 <- 3*runif(N)
mu <- c(-1,0,1,2)[as.numeric(X3)]
Y <- X1**1.5 + 2 * (X2**.5) + mu + rnorm(N,0,sigma)
data2 <- data.frame(Y=Y,X1=X1,X2=X2,X3=X3,X4=X4,X5=X5,X6=X6)
# predict on the new data using "best" number of trees
# f.predict generally will be on the canonical scale (logit,log,etc.)
f.predict <- predict(gbm1,data2,best_iter)
# least squares error
print(sum((data2$Y-f.predict)^2))
#> [1] 5024.826
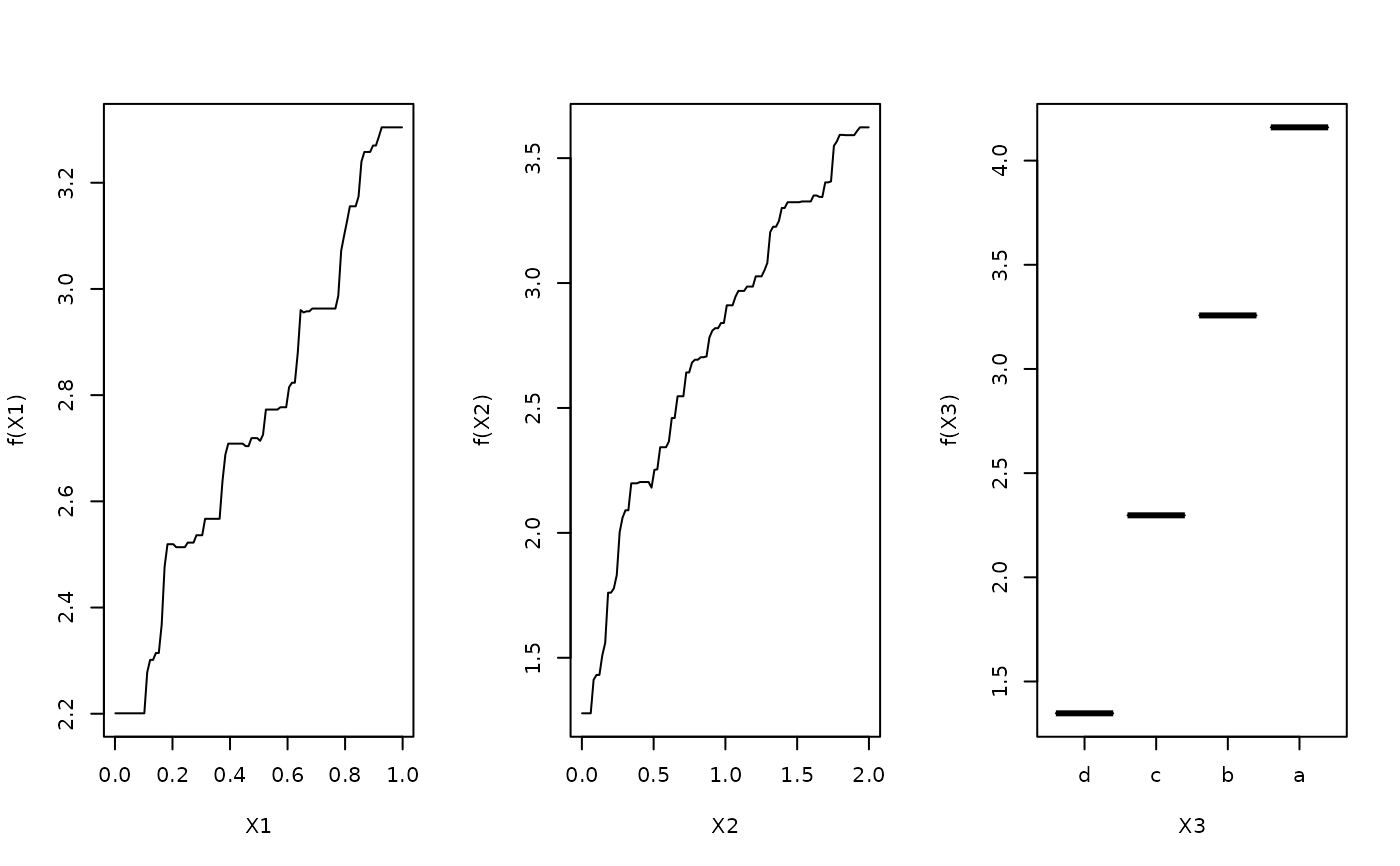
# create marginal plots
# plot variable X1,X2,X3 after "best" iterations
oldpar <- par(no.readonly = TRUE)
par(mfrow=c(1,3))
plot(gbm1,1,best_iter)
plot(gbm1,2,best_iter)
plot(gbm1,3,best_iter)
#> var rel_inf
#> X3 X3 63.2461194
#> X2 X2 28.7697296
#> X1 X1 5.9798260
#> X6 X6 1.1201571
#> X4 X4 0.7813982
#> X5 X5 0.1027697
# compactly print the first and last trees for curiosity
print(pretty_gbm_tree(gbm1,1))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction Weight
#> 0 0 0.5169642128 1 5 6 30.69864 250
#> 1 2 0.5000000000 2 3 4 70.28915 67
#> 2 -1 -0.0974371920 -1 -1 -1 0.00000 23
#> 3 -1 0.0104230254 -1 -1 -1 0.00000 44
#> 4 -1 -0.0266036164 -1 -1 -1 0.00000 67
#> 5 -1 0.0208285473 -1 -1 -1 0.00000 68
#> 6 2 2.5000000000 7 8 9 107.52019 115
#> 7 -1 -0.0290981596 -1 -1 -1 0.00000 83
#> 8 -1 0.0787840681 -1 -1 -1 0.00000 32
#> 9 -1 0.0009212429 -1 -1 -1 0.00000 115
#> Prediction
#> 0 -0.0010406326
#> 1 -0.0266036164
#> 2 -0.0974371920
#> 3 0.0104230254
#> 4 -0.0266036164
#> 5 0.0208285473
#> 6 0.0009212429
#> 7 -0.0290981596
#> 8 0.0787840681
#> 9 0.0009212429
print(pretty_gbm_tree(gbm1,gbm1$params$num_trees))
#> SplitVar SplitCodePred LeftNode RightNode MissingNode ErrorReduction Weight
#> 0 1 1.2225338528 1 5 9 0.3614331 250
#> 1 5 0.2508527830 2 3 4 0.2505685 145
#> 2 -1 0.0041388708 -1 -1 -1 0.0000000 15
#> 3 -1 -0.0026860866 -1 -1 -1 0.0000000 130
#> 4 -1 -0.0019800565 -1 -1 -1 0.0000000 145
#> 5 5 2.2890534288 6 7 8 0.4646160 105
#> 6 -1 0.0035842050 -1 -1 -1 0.0000000 83
#> 7 -1 -0.0045884162 -1 -1 -1 0.0000000 22
#> 8 -1 0.0018718463 -1 -1 -1 0.0000000 105
#> 9 -1 -0.0003622573 -1 -1 -1 0.0000000 250
#> Prediction
#> 0 -0.0003622573
#> 1 -0.0019800565
#> 2 0.0041388708
#> 3 -0.0026860866
#> 4 -0.0019800565
#> 5 0.0018718463
#> 6 0.0035842050
#> 7 -0.0045884162
#> 8 0.0018718463
#> 9 -0.0003622573
# make some new data
N <- 1000
X1 <- runif(N)
X2 <- 2*runif(N)
X3 <- ordered(sample(letters[1:4],N,replace=TRUE))
X4 <- factor(sample(letters[1:6],N,replace=TRUE))
X5 <- factor(sample(letters[1:3],N,replace=TRUE))
X6 <- 3*runif(N)
mu <- c(-1,0,1,2)[as.numeric(X3)]
Y <- X1**1.5 + 2 * (X2**.5) + mu + rnorm(N,0,sigma)
data2 <- data.frame(Y=Y,X1=X1,X2=X2,X3=X3,X4=X4,X5=X5,X6=X6)
# predict on the new data using "best" number of trees
# f.predict generally will be on the canonical scale (logit,log,etc.)
f.predict <- predict(gbm1,data2,best_iter)
# least squares error
print(sum((data2$Y-f.predict)^2))
#> [1] 5024.826
# create marginal plots
# plot variable X1,X2,X3 after "best" iterations
oldpar <- par(no.readonly = TRUE)
par(mfrow=c(1,3))
plot(gbm1,1,best_iter)
plot(gbm1,2,best_iter)
plot(gbm1,3,best_iter)
 par(mfrow=c(1,1))
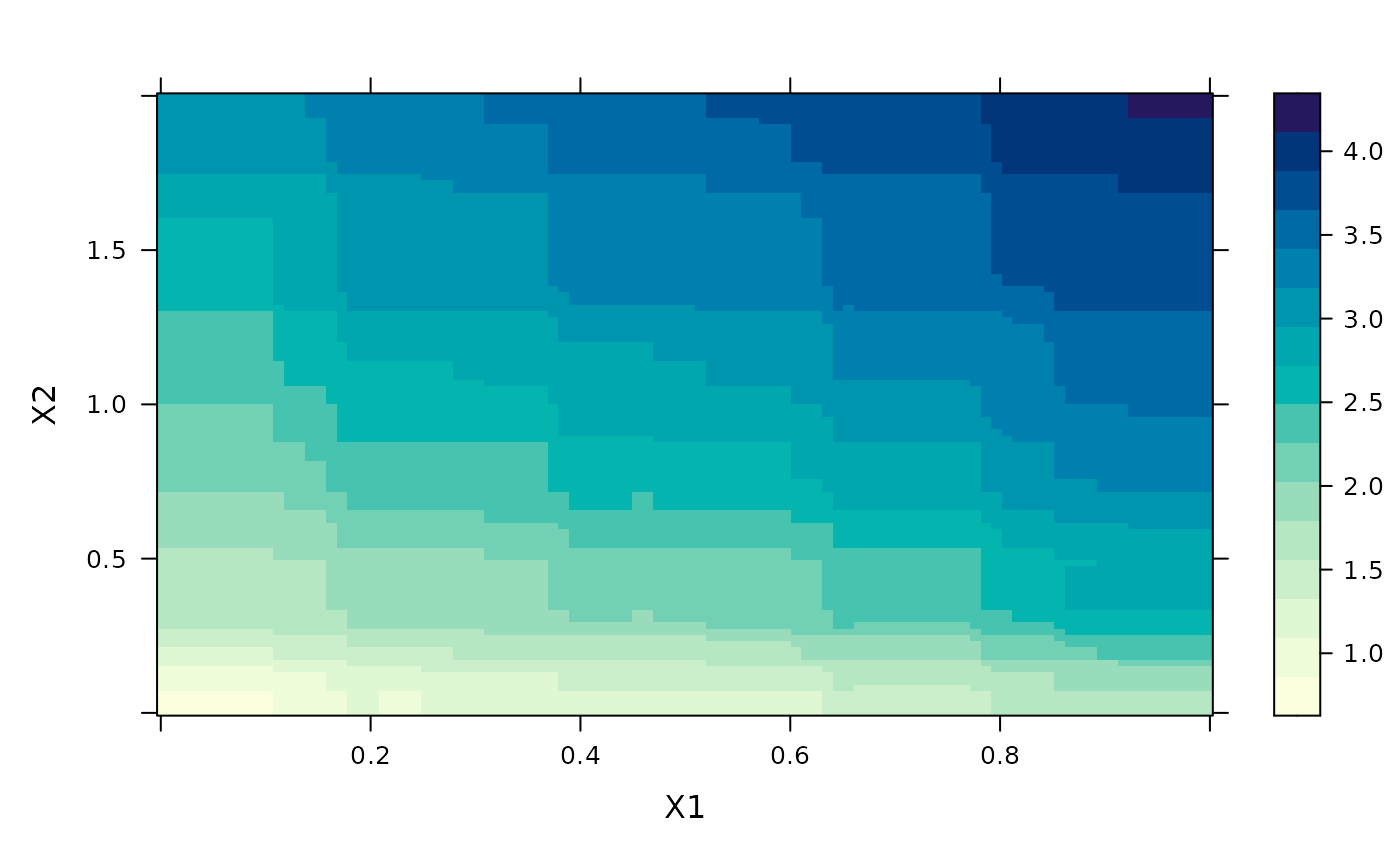
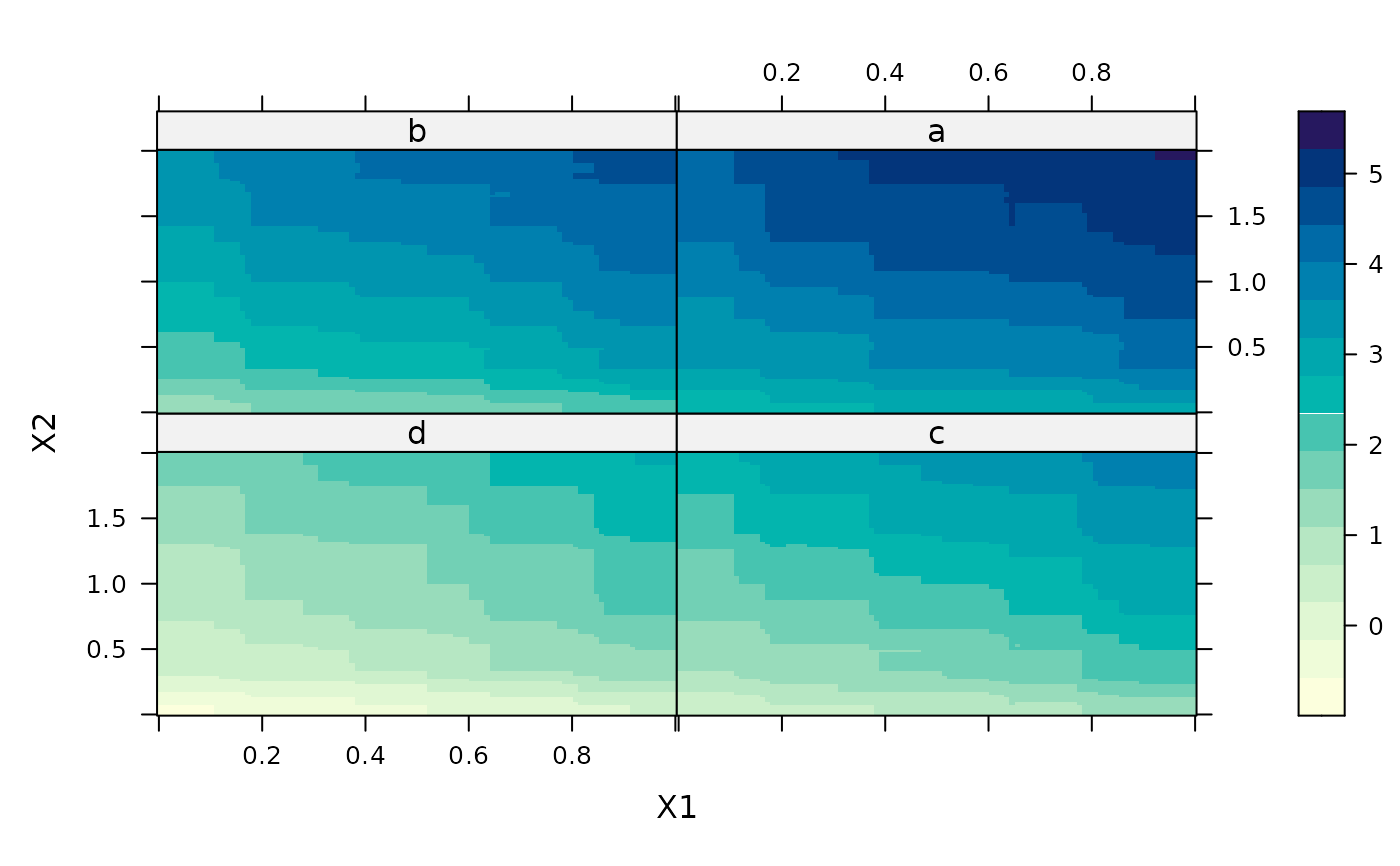
# contour plot of variables 1 and 2 after "best" iterations
plot(gbm1,1:2,best_iter)
par(mfrow=c(1,1))
# contour plot of variables 1 and 2 after "best" iterations
plot(gbm1,1:2,best_iter)
 # lattice plot of variables 2 and 3
plot(gbm1,2:3,best_iter)
# lattice plot of variables 2 and 3
plot(gbm1,2:3,best_iter)
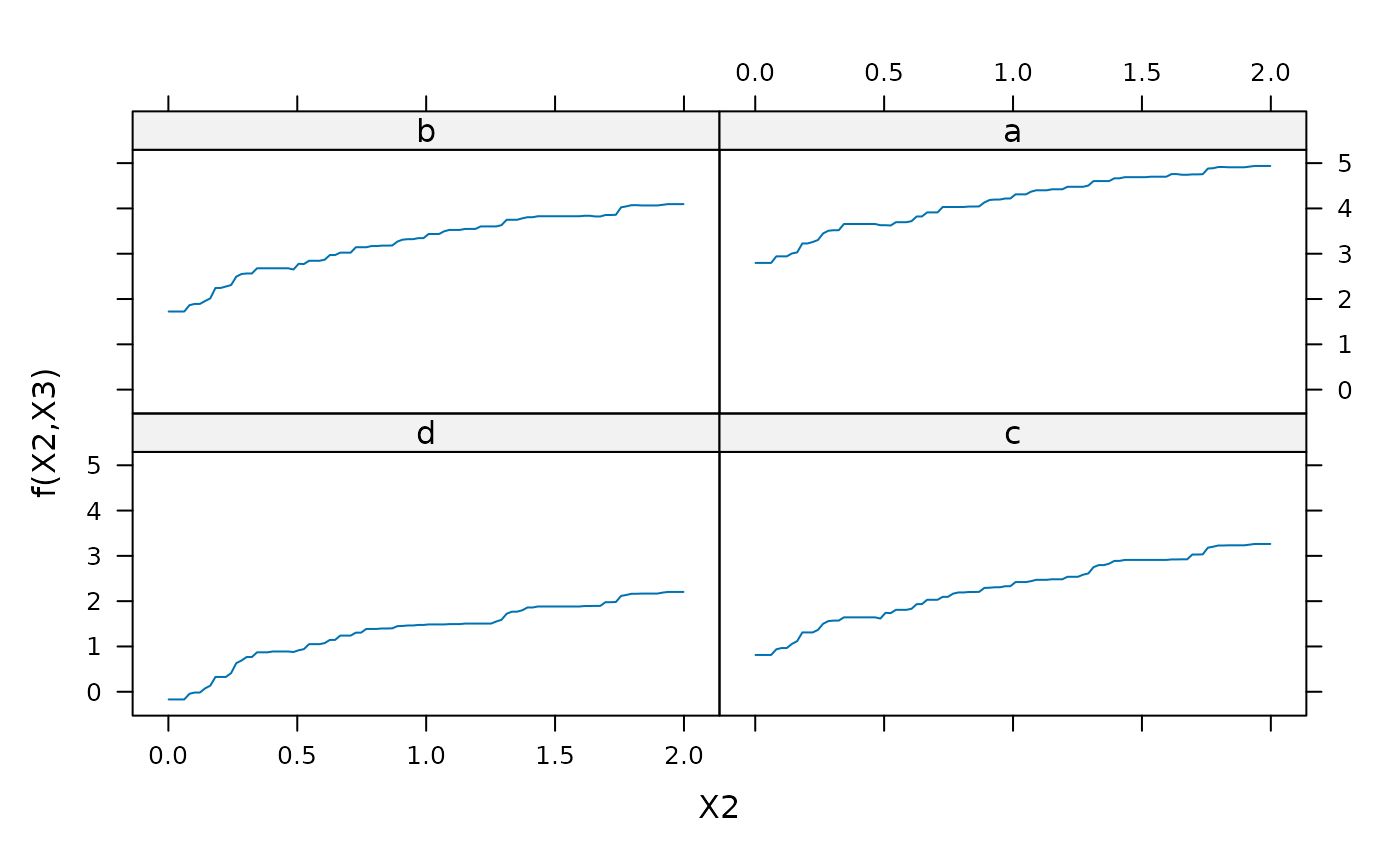 # lattice plot of variables 3 and 4
plot(gbm1,3:4,best_iter)
# lattice plot of variables 3 and 4
plot(gbm1,3:4,best_iter)
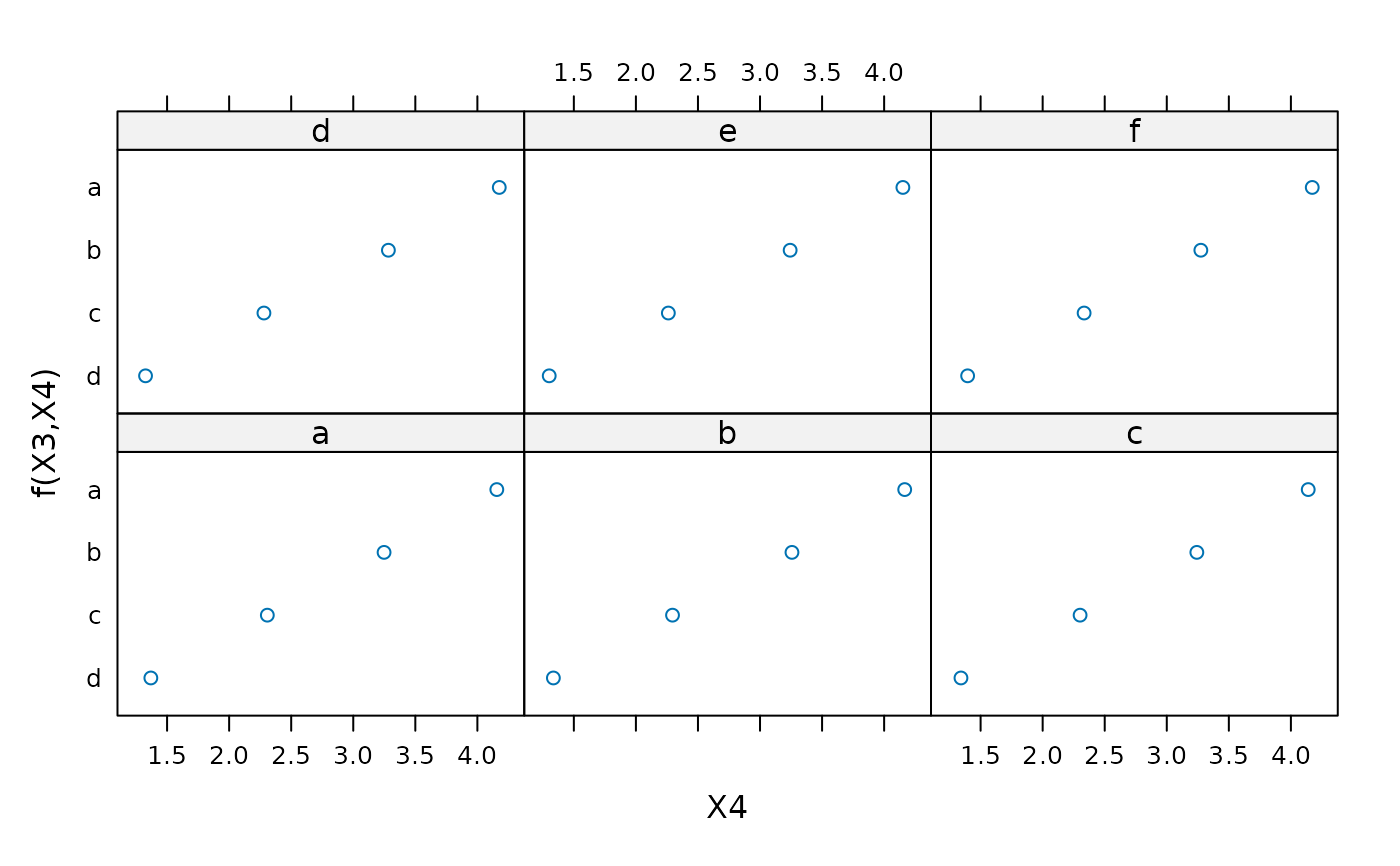 # 3-way plots
plot(gbm1,c(1,2,6),best_iter,cont=20)
# 3-way plots
plot(gbm1,c(1,2,6),best_iter,cont=20)
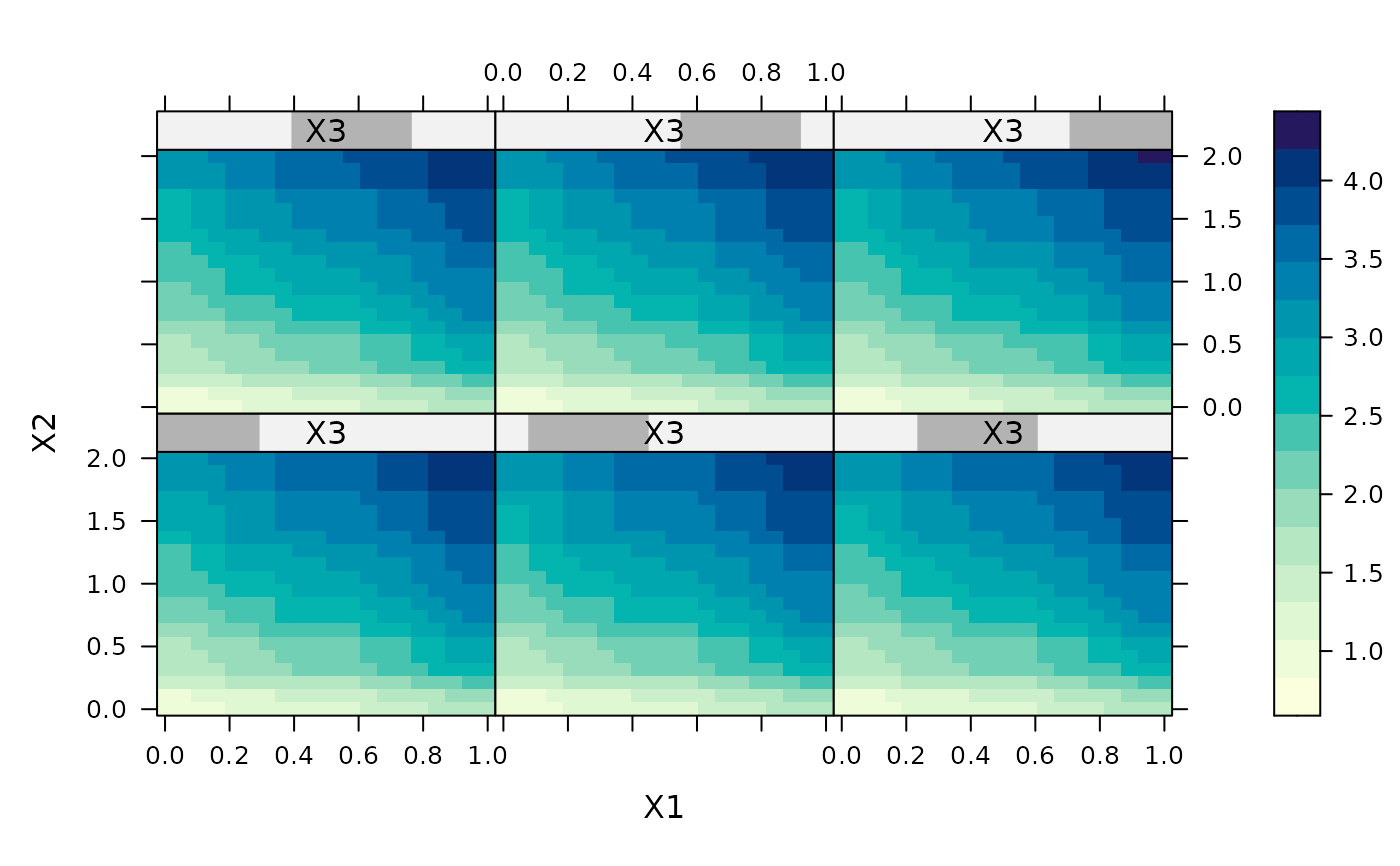 plot(gbm1,1:3,best_iter)
plot(gbm1,1:3,best_iter)
 plot(gbm1,2:4,best_iter)
plot(gbm1,2:4,best_iter)
 plot(gbm1,3:5,best_iter)
plot(gbm1,3:5,best_iter)
 par(oldpar) # reset graphics options to previous settings
# do another 100 iterations
gbm2 <- gbm_more(gbm1,100,
is_verbose=FALSE) # stop printing detailed progress
#> Warning: gbm_more is incompatible with cross-validation; losing cv results.
par(oldpar) # reset graphics options to previous settings
# do another 100 iterations
gbm2 <- gbm_more(gbm1,100,
is_verbose=FALSE) # stop printing detailed progress
#> Warning: gbm_more is incompatible with cross-validation; losing cv results.